How to Use the Process Analyzer in Existing Apps
Create the mpmX Data Model
To use the Process Analyzer in an existing app, you need to first create the mpmX Data Model. There is two ways you could do this:
-
Using the mpmX Template App as described in Fill the Template App with Process Mining Data
You first need to set the variable:Let mvStorempmXModelQVD = 1;Thus, the mpmX Data Model will be stored in the data connection were the event log table came from.
-
Using the mpmX EventlogGeneration Apps as described in Create an Event Log from your Data Source
The mpmX Data Model will be automatically stored in the folder $(DataConnection)/03_ProcessLogGeneration/mpmX_Model, where $(DataConnection) is the data connection defined for the process mining project described in Folder Structure.
Load the mpmX Data Model into the existing app
The tables you need depend on the use case. Here are the three versions:
- full-blown
- minimal
- conformance checking
1. Full blown
If you want to combine the BI-Dashboards with the full blown mpmX capabilities, you may load the whole model into the app (up to 12 tables, including conformance checking, custom lead times and the process path continuation).
2. Minimal
Load the minimal model. This includes only the tables AL_ActivityTypes_Helpdesk, pa_activity_log_Helpdesk, pa_process_variants_Helpdesk.
This version allows to use the mpmX extensions ProcessAnalyzer, QueryBuilder and ProcessModeler in the existing app but does not blow up the data model.
3. Conformance Checking
For Conformance Checking you will need to load
- the minimal model
- all tables that include "conformance" in their name
- the table "BehaviourInModel"
Combine the model parts
The mpmX Model tables will connect automatically via their key fields.
To connect the mpmX Model tables to the rest of the apps BI-Data Model, you need to create a connection to the field CaseID.
If your data model is developed as a star scheme (recommended for higher app performance) you will probably want to connect the mpmX Model directly to your central table. Let's call this the FACTS table for the moment.
💡 Note: The aim of the modelling should be that if you select a field value in the FACTS table, the complete process instance is shown in the mpmX ProcessAnalyzer.
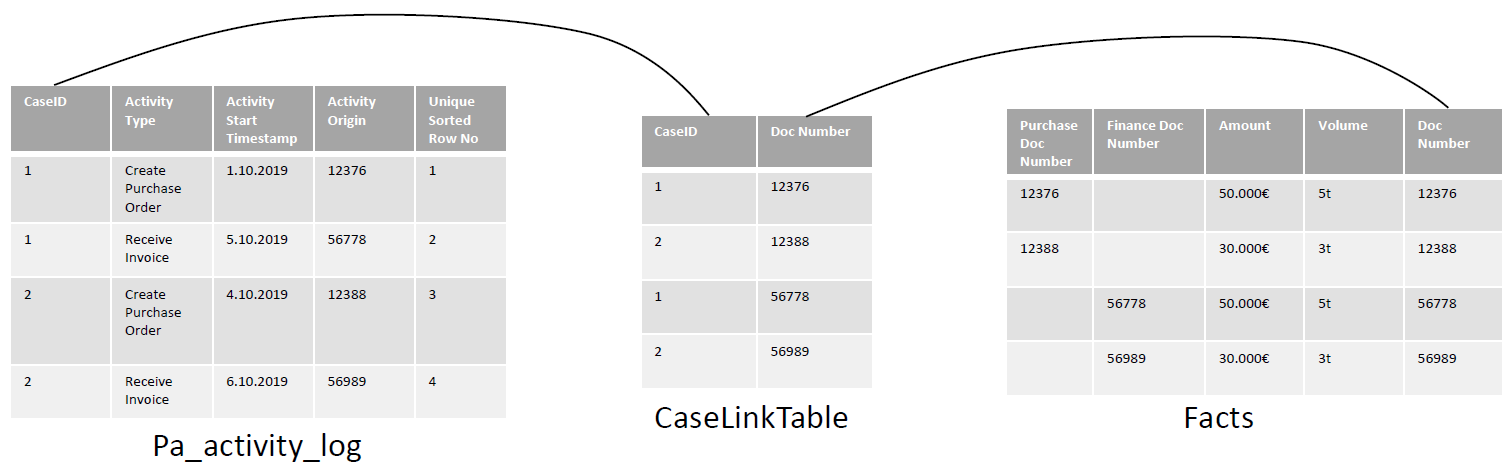
- Therefore, it is necessary to connect to the CaseID of the pa_activity_log.
- Similarly, if a specific CaseID is selected, we would expect to see every entry in the FACTS table that is related to that case.
If this FACTS table has a 1:1 relationship to the CaseID, create the field "CaseID" in the FACTS table. The two model parts will then connect.

If the FACTS table has a n:1 relationship with a case, then you should create a CaseLinkTable.
- This might happen if your FACTS table consists of, for example, the single documents of your transactional source system which are also the base of the process's events. One case, then, can have several entries in FACTS table.
- We recommend the same if the FACTS table has a 1:n relationship with a case (e.g. the app is concerned with supplier analytics, one row in the FACTS table is a supplier, but one supplier can have various processes connected to it).
💡 Hint: For more information on how to enhance the app see teh Business Analyst Guide, for instance Create a Guided Tour .